Over the last few weeks, I’ve been working on a side project to generate a documentation Web site using Metalsmith for any linked data vocabulary. Today I published the repository to GitHub and the package to NPM. There are already a lot of improvements that I plan to make as I evolve the project, but I’m excited to get this first version out there and look forward to getting your feedback.
Background
As I’ve said many times over the last couple of years, I believe that one of the key problems that we have when it comes to building systems of all types is the lack of a unified data model. Instead we have implementation-specific schemas that we call data models. For example, were I to walk up to most enterprise developers and ask them to show me their data model, they would likely show me an ER diagram for their relational database. And while it’s possible to get away with this while the system and maintaining team is small, it RDBMSs become an insufficient lens for expressing and allowing comprehension of a data model as it grows and federates over time. I believe this insufficiency to be based on two primary factors. First, the rules of good RDBMS design - specifically, normalization - are solving for problems of storage and access efficiency rather than logical information architecture. Secondly, the key feature of an RDBMS - the relationship - is largely structural in nature rather than semantic. Tables are related to one another by mapping columns in one table to columns in another. Some level of semantics can be conveyed by careful naming of those columns, but that information is still germane to the entities and not the relationships. Further, because RDBMS relationships also carry the responsibility of ensuring consistency, certain types of semantics like directionality are implicit and are surfaced, if at all, through the queries that are executed on top of the schema.
As I mentioned, using an RDBMS as a data model can become more problematic as the model grows (both in size and complexity) and federates into services owned by different teams. What I’ve observed most often when systems evolve this way is that the data model shifts to the document schemas that define the different service interfaces. Back in the “old days”, it was XML Schema - nowadays it is JSON-schema. But as with RDBMSs, using document schemas as a lens for data modeling is not without its own problems. The biggest problem (as I’ve discussed in the past) is local scope. Each service’s document schema defines the concepts and terms for that service. And what that inevitably means in a system made up of a network of services is that the same concept will end up being described by multiple terms and the same term can end up defining multiple (and potentially conflicting) concepts. Companies will typically deal with this in one of two ways: acceptance and governance. In the case of the former, document schemas are accepted as incomplete (they may even by made intentionally vague) and a tribal knowledge starts building to fill in the gaps. In the latter case, the company forms some kind of central committee that enforces consistency across all service definitions and schemas. Neither of these scenarios works in the company’s interests: the former yields a lesser quality ecosystem of services; the latter yields an organizational bottleneck that undermines the reason the company probably created a federated topology in the first place.
If neither the RDBMS nor the document schema are the right tool for building a data model, what is the right path? In my opinion (which shouldn’t be shocking by this point), that “path” is a directed graph (pun not intended, but still funny)- and tools like RDF, RDFS, and OWL are the way of defining that graph. Recently, there have been several great examples of systems that have been built to take advantage RDF-based vocabularies. However, there still hasn’t been much general adoption - particularly in the enterprise space. I believe that one of the big reasons for this is a lack of higher level tools. No matter how expressive a graph may be in describing a real-world data model, humans tend to have a harder time reasoning about a graph. Higher level tools for visualization and documentation can make graph-based data modeling more approachable and hopefully then more practiced. A great example over in recent history is the Web site https://schema.org. This site is a collaboration between a bunch of big technology companies to define a set of linked data vocabularies that can be broadly utilized. However, the greatest aspect of the site (IMO) is that it makes provides documentation for all of the named terms (remember that according to the rules of linked data, every name is a fully-qualified URL).
Schema.org for Everyone
I’ve been a big fan of using terms from schema.org for a while. However, I also have my own vocabularies to manage and part of maintaining a usable vocabulary is to have good documentation. So I was disappointed when I couldn’t find a good way to take an RDF schema document and produce a site like schema.org. When a recently started working with Metalsmith, I was inspired by their plugin model and decided to take the opportunity to write a plugin that could read RDF and product a static schema.org-like Web site. This week I was finally able to release that work.
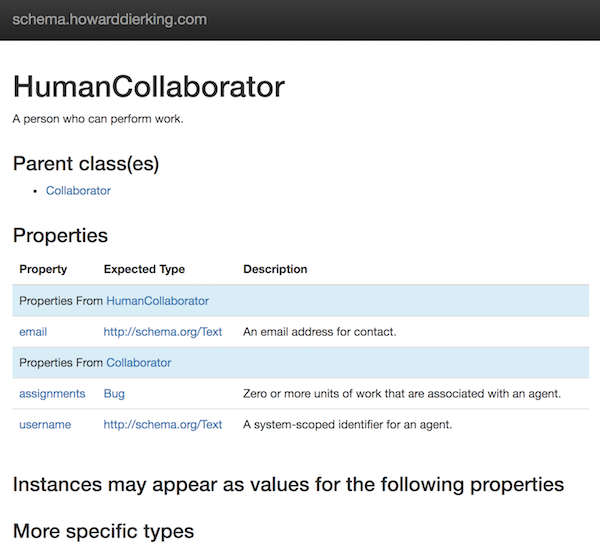
As mentioned, the plugin searches for all RDF documents (currently limited to those serialized as JSON-LD) and generates static pages for each type and property based on the templates that you supply. As illustrated by the reference site, the Metalsmith configuration is pretty simple (assuming you’re familiar with Metalsmith; if not, read the getting started docs real quick):
const metalsmith = require('metalsmith');
const layouts = require('metalsmith-layouts');
const ldschema = require('metalsmith-ldschema');
const permalinks = require('metalsmith-permalinks')
metalsmith(__dirname)
.source('./src')
.destination('./site')
.use(ldschema({
classLayout: 'class.html',
propertyLayout: 'property.html'
}))
.use(permalinks({
pattern: ':title'
}))
.use(layouts({
engine: 'qejs',
directory: 'layouts',
R: R
}))
.build(function(err){
if(err)
console.error(err)
else
console.info('Site build successful!');
});
All you need to do is specify which layouts you want to use for classes and properties. The plugin will then read your RDFS documents, build a graph, and then process each node through the appropriate template. From an API point of view, each term found is exposed to the template as, appropriately enough, term. Both classes and properties are exposed as term in case you want one template for both. However, depending on the type of term (e.g. class or property), you’ll see different values.
For both classes and properties, you can expect the following values:
| value | type | description |
|---|---|---|
id |
string | The fully qualified URI identifying the term, specified in JSON-LD with the @id keyword |
label |
string | A short description of the term, specified using the RDFS label relationship |
comment |
string | A longer description of the term, specified using the RDFS comment relationship |
path |
string | A relative path to the extensionless term id |
fileName |
string | The name of the term file with file extension (e.g. html) |
If term is an rdfs:Class, you can expect the following values:
| value | type | description |
|---|---|---|
parentClasses |
array | The list of zero or more parent classes, specified using the RDFS subClassOf relationship |
childClasses |
array | The list of zero or more child classes, specified using the RDFS subClassOf relationship |
properties |
array | The list of zero or more properties belong to this class, specified using the schema.org domainIncludes relationship |
valueFor |
array | The list of zero or more properties for which this class may be a value, specified using the schema.org rangeIncludes relationship |
If term is an rdf:Property, you can expect the following values:
| value | type | description |
|---|---|---|
usedOn |
array | The list of zero or more classes that the property can be found on, specified using the schema.org domainIncludes relationship |
expectedTypes |
array | The list of zero or more classes that can define the value of the property, specified using the schema.org rangeIncludes relationship |
As I mentioned, this is a Metalsmith plugin, so it doesn’t try to actually build HTML markup for you, but rather exposes the relevant term object to a template that you define and maintain. As such, you can bring your favorite template engine. In the reference application, I chose qejs, which is an asynchronous version of the popular ejs template engine. The template code looks like the following.
<div class="row">
<div class="col-md-12">
<h1><%= term.label %></h1>
<p><%= term.comment %></p>
</div>
</div>
<div class="row">
<div class="col-md-12">
<h3>Parent class(es)</h3>
<ul>
<% R.forEach(p => { %>
<li><a href="<%=p.path%>"><%= p.label %></a></li>
<% }, term.parentClasses); %>
</ul>
</div>
</div>
As you can hopefully see, at the point of building your template, there’s nothing special going on - just use the term object like any other bit of data that is available to the template.
Features
This is a first version. However, I think that I’ve covered most of the core features of https://schema.org with the current features. In fact, there are some niceties in the feature set that were largely driven by some things that I wasn’t a huge fan of in the schema.org’s repository.
- You can split your RDFS documents into multiple files. The plugin will find all
*.jsonldfiles and merge them into the same graph in memory prior to rendering pages. - The plugin surfaces relationships like domain and range in a bi-directional fashion between properties and their associated classes. For example, in the case of a property, range defines the expected types for a value of that property. The plugin adds this relationship to the property in the form of
expectedTypes, but it also adds the relationship to the associated classes in the form ofvaluesFor. There are similar bi-directional bindings for domain (which specifies what properties can be used on what classes). - Class hierarchies are supported (also in a bi-directional manner) and by traversing the objects, you can create visualizations to illustrate rudimentary inference rules like the type propagation rule.
In general, the plugin enables creation of a Web site that is reflective of the underlying graphical model. As you can hopefully see from the reference application, you can spend as much time as you want (or have) browsing the data model.
Future Improvements
- The RDF serialization is currently limited to JSON-LD. That also means that comprehensions are based on JSON documents. I have an idea on how to improve both of these aspects, so hopefully soon will be able to support multiple RDF serializations.
- I’m investigating whether or not to support
rdfs:domainandrdfs:rangerather than the more scoped schema.org versions. This could open up more opportunities for providing documentation/explanation around inferencing. - Speaking of inferencing, I’m looking to use this project as a means to help surface and explain RDF inferencing rules. This is a topic that tends to get abstract pretty quickly, but it is one of the most powerful features of this modeling approach, and I would like to see this project contribute to advancing the understanding and usage of RDF, RDF-schema, and inferencing.
Relationship to Service Descriptions and Document Schemas
If you’re a service developer, you’re probably scratching your head and asking, “how am I supposed to build a service or client to this?” It’s a fair question. Nowhere in this model, will you see things that resemble the parameter bindings that you may expect. There are no ‘required’ fields, no reserved words for programming language type system bindings, no guidance of what a document structure should look like in a service call.
There are linked data vocabularies that can enable you to to create services and clients that communicate via linked data. However, let’s take baby steps here and say that for the purpose of this discussion, the linked data model exists for two purposes:
- It lets you reason about your data free from the constraints of storage format or data transfer format.
- It gives you globally-scoped names that you can embed in your service payloads (JSON-LD gives you a convenient means of accomplishing this).
As such, you can continue building services using the same approaches that you’ve been using with the single embellishment of a linked data context that provides global scope for names. In parallel, the linked data vocabulary creation exercise will give you a stronger understanding of the data behind your business, enabling you to then build better APIs, regardless of whether you ever go all the way down the semantic Web path.
If nothing else, I hope that this exposes you to Metalsmith, as I think it’s a truly stellar static site generator.