We all have see them; most of us have to deal with them; many of us contributed to writing at least one of them. Legacy code bases tend to evolve over decades and will with rare exception get messier and more entangled as a function of the number of people working on the project and the lines of code they produce (a phenomenon that seems pretty consistent with the rest of the known universe). My company was recently challenged to take our ~17 year old code base and make a fundamental architectural shift from a more traditional layered monolithic architecture to a micro-service one. Coupled with that architectural goal, we also want to start moving as many services as possible to public cloud providers in order to take advantage of the elasticity that the cloud can provide.
To be clear, the existing code base has done its job quite well. The fact that 17 year old Web code even exists speaks a lot about its value. The The problem is that, like many code base’s of the same size and age, the system has grown to the point where adding new capabilities is becoming increasingly difficult. This problem along with one of needing to increase scale and drive down costs are big drivers behind the architectural shift described above. However, changing a monolith to a set of micro-services has its own set of challenges.
What follows is a position paper in which I propose 2 high level constraints for teasing apart components of a monolithic application architecture into a set of micro-services. I would love your feedback.
Teasing Apart the Monolith
Driving new and legacy systems integration by applying constraints in the areas of networking and data flow
Abstract
The following position paper outlines some of the technical challenges that we face in making the transition from a monolithic architecture to a set of distributed, loosely-coupled services, and it proposes an architectural solution for integrating new services with existing data center-hosted components. The approach presented has a bias towards preventing architectural bleed from the current monolith into the evolving distributed service-based architecture.
Background
Our current product is a Web application built in a classical n-tier architectural style. While our business domain has expanded over the years and though new technology has been integrated into the product, the core conceptual architecture remains unchanged and, while a generalized view, resembles the following.
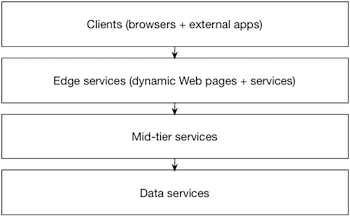
In a generic sense, there is nothing fundamentally wrong with this architectural approach. However, in practice, there are few challenges that can emerge as the business and technical domains grow. Most notable in our experience are the following.
- The code and infrastructure for all components and layers of the product is collocated in the same source tree. This results in a single build process, and subsequently, a single release cadence for every component of the product. It also can lead to unintentional coupling between components. One of those most insidious examples of this coupling is the emergence of “integration by shared table” whereby integration is achieved by having different services write to and read from each others private storage.
- As the amount of low-level coupling increases, there is a natural increase in complexity for both the runtime infrastructure as well the build and deployment process. Naturally, an increase in complexity also increases the probability of failure in delivering software, which over time can reduce the velocity in delivering value to customers.
In order to reduce the cost of running the system and increase its reliability, our engineering leadership has identified a shared-nothing, Microservice-based architecture as the path forward. In this architectural style, the business domain is partitioned vertically, technology and design choices (from code to data persistence) are implementation details of those vertical silos, and integration occurs through well-defined service contracts and supported by published SLAs. An example of this design resembles the following.
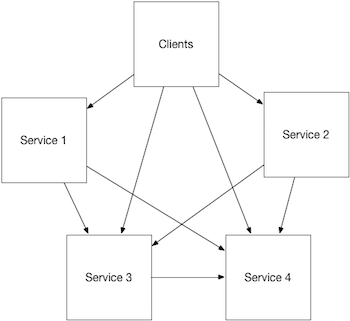
This shift in architectural approach provides for a number of benefits and specifically addresses the previously aforementioned challenges in the following ways:
- Code and infrastructure configuration assets are individually maintained for each of the identified services. Services interoperate only via published service contracts. Additionally, there are no shared resources like databases between services.
- The runtime infrastructure is tailored to the needs of the individual services, and is not shared between services. As a result, each service is able to evolve and scale independently of any other service.
The combination of these 2 characteristics virtually eliminates the low level coupling between components, yielding a system design that provides for faster delivery of functionality while reducing risk in terms of the scope that can be impacted by an outage of any one service. Additionally, because the runtime architecture can be tailored to the needs of an individual service, operational expenses can be driven down across the system.
Challenges
Setting forth a goal of decoupling a monolithic architecture into a set of independent, cooperating services is a relatively easy thing to say, but a much more difficult task to implement. A few concrete challenges include the following:
- Much of the functionality that would be identified for inclusion in a discrete service has been duplicated and scattered throughout the monolithic code base
- Integration between logical groups of functionality is accomplished many times by low level code sharing and, in many cases, shared database structures
- Even if related functionality were separated into cohesive groups of service code, those services would not be designed for non-functional concerns such as security scalability and resiliency. This is because the monolith has historically handled these concerns.
Many of the strategies put forth for untangling the monolith have involved building new services that call into the existing legacy systems as well as each other. This topology is illustrated below.
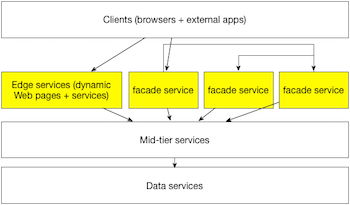
While this approach would yield a new, and ideally cleaner API layer, it fails to solve the underlying aforementioned problems. For example, the new APIs would not be a driver to eliminate any of the logic that has been sprinkled across the monolith. This phenomenon would necessarily cause an increase in complexity of the new API code, as it would have to be aware of the underlying service logic. Further, because so much cross-service integration has been performed at the data storage layer, the service would need to also be aware of how the data is ultimately stored. Finally, there is no incentive for new service code in this model to be made any more secure or resilient than the current service code, as it would remain protected by the monolith’s network architecture and dependent on the underlying monolith for availability.
A variant of this strategy attempts to remove coupling to the shared data store by having each service own its own storage and then synchronize that store with the legacy data store. However, this strategy suffers from many of the same issues as the previous example and adds the complexity of data synchronization when much of the legacy business logic exists in the legacy database’s stored procedures.
In order to achieve the goal of independent, cooperating services, there must be a forcing function. This paper argues for the application of architectural constraints to drive decoupling between services and provide a single focus and single point of accountability for each individual service.
Solution
A look at many of the strategies for extracting new services from the monolith reveals many of the same underlying problems regardless of approach. However, all of these strategies have at least one common assumption: the direction of the data flow between new and legacy services will be bi-directional. This assumption – that new services will necessarily make remote procedure calls into the legacy services – automatically adds the following additional assumptions:
- New services should be protected by the existing network architecture since they will be calling into the already-protected services.
- Assumptions can be made based on knowledge of the legacy system where data will ultimately reside. As a result, even well intentioned service designers can take shortcuts (sometimes unintentionally) resulting in tight coupling of new services to legacy.
- By deploying new and old services in the same runtime environment, the release cadence for new services will be constrained to the cadence of the legacy systems.
If the common denominator between the different problematic approaches is the directionality of data flow between new and legacy systems and the network collocation required by it, consider a service topology where data flow was constrained to be uni-directional. Because this constraint removes the additional assumptions required by a bi-directional approach, we can then add another constraint: that each new service is pushed outside of the existing network.
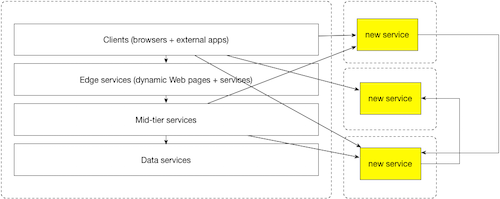
In this constrained model, each service must exist in its own virtual network (represented by the dashed lines) and this network must not be bridged to the legacy network. This network isolation, then forces communication between services to happen at the application protocol level – two specifically - HTTP(s) and DNS. The constraint yields the following benefits to the overall system architecture:
- Service teams are able to be end-to-end accountable for their service
- Service teams are forced to think about their service boundary and the related considerations such as security, scalability and resiliency
- Services can be independently managed and released. Additionally, optimizing individual components of a service, such as middleware or a database, is simplified by the fact that no other service accesses these components directly.
- Defense in depth is a natural side effect of the design since no service has back door access to any other service.
- DNS as the means of partitioning services enables a coordinated view of the overall service topology, both from a logical and security perspective (e.g. the wildcard certificate *.api.mydomain.com can be used to provide uniform TLS across all services, regardless of the service’s address). It also simplifies partitioning and routing services based on a variety of factors, such as geo-distribution (e.g. service.emea.api.mydomain.com).
- It shifts the conversation around “internal vs. external” services to one around authorization to different services. This is because all services are effectively public.
The second constraint illustrated above diagram is in the directionality of calls between new and legacy services. It constrains data to flow in only one direction - outward from legacy services into new services. Over time, the directionality constraint will likely be retired as there will be less “legacy” functionality. This constraint yields the following benefits to the overall system architecture:
- There is no incentive for a new service team to invest in putting data in multiple places or making multiple calls to the legacy system in order to satisfy backwards compatibility requirements. In practice, satisfying these kinds of requirements unnecessarily increases the complexity of the new service and removes the incentive for legacy service teams to move forward with improving their own architecture.
- By forcing legacy systems to call out to new services, the new services are able to gain a better understanding of the specific use cases that they need to be able to handle
- It enables the new services to release and scale independently of the legacy system or release process
- It enables the new service to remain focused the unique business value it provides and not on understanding the semantics and syntax of integrating with legacy systems.
Authorization
As mentioned, one of the outcomes of a distributed set of cooperating services is that each service must be accountable for managing its own security boundaries. This rightly forces the question of how services should be authenticated and authorized to one another. While outside the direct scope of this paper, 2 of the more obvious options to consider are the following:
- Each service is able to authenticate and authorize other services using x.509 certificates. While this appears to be a valid approach from a pure security perspective, it could prove problematic with respect to scale; since in order to allow for different authorization policies for different services, each service would be required to maintain its own policy definitions for the services that it interacted with.
- Building on the previous, an improved approach would be to have services authenticate using an x.509 certificate to a security token service. In exchange, the STS would issue a token that included with it a set of claims. Downstream services that need to provide authorization can then use the set of claims without needing to maintain any details about the caller.
Managing the Chaos
While there are many benefits from this federated approach, there are still certain functions that should be centralized, for both practical and sometimes compliance reasons. A good example of this is logging. While logs should be the domain of the individual services, logs must also be able to be combined, correlated and made searchable. This is important for both analysis activities as well as for compliance regulations (e.g. non-repudiation).
These types of non-functional requirements should be made a part of the service-level agreement that each service provides, but should not be made into technical constraints in and of themselves. In the case of logging, the requirement is that each service should be externally monitorable and that logs should be made available for aggregation. The impact of this is that each service must expose its logs for consumption by another service. That service is granted authorization rights to the logs using the techniques identified above. Further policy such as supporting correlation IDs should also be considered as an effective tool for tying a logical operation together across multiple services. Note that this requirement does not impose a technical constraint on the service (e.g. that service code must be coupled to a central logging system) – only that the logs must be made available for collection and correlation. This same principle should apply to key metrics data that will be common to all services.
The Role of Operations and Service Management
This model for constructing services fits in nicely with a devops organizational model, and while a discussion of devops is beyond the scope of this paper, it may prove worthwhile to at least mention the ideal role of shared services teams in this model.
In the current architecture, much of the expertise around security, network design, and planning for scale, resiliency, etc. is held by individuals in these shared teams. The proposed federated model will be nearly impossible to scale in practice unless this expertise can be disseminated into the teams. As such, it is recommended that a percentage of service management and operations personnel be collocated with the feature teams that are constructing the services. This will better enable them to be a part of the process, from design to runtime, and it will help to educate the development teams on the pain points and requirements of managing a production service. A central, shared service team should also remain in place for working on systemic issues such as bottlenecks between services and correlation of failures across services.
Assumptions and Caveats
- In order to prevent a ground-up explosion of Microservices that have duplicate functionality and ill-defined SLAs, one of the precursor inputs needed for this process is a top-level partitioning of the service domain and a possible reorganization of engineering staff to align to these partitions.
- This architectural model assumes a reasonable amount of tolerance for eventual consistency, which appears to be reasonable in the majority of our use cases. Scenarios that require full consistency may require a different architectural approach. However, these are likely the exception rather than the rule.