I’ve been going around to different teams inside of my company recently and talking about how we’ve gone about the task of selecting different tools and technologies for our projects. I figured that if this many people inside the company were curious, there may be some value in sharing it with you good folks as well. So here, I’ll attempt to cover the principles, strategies, and technologies for both our development process/pipeline and our projects themselves. And as always, I would love to hear your experiences - especially if your experience provides insight that can help us further improve the ways that we do things.
Our Projects
My team has projects that go in a few different directions, but at a high level, we have 2 buckets of work. The first is developer experience. This includes everything from the developer portal and documentation Web site to client libraries in a variety of different languages. The second bucket cloud services. This particular work stream is not exclusive to us - there are a variety of teams around the company that are working on various Web services and even some that are positioning those services to run in the cloud. However, our team is unique in that we have taken a “public cloud-first” approach to everything that we build and as a result have been one of the first teams in the company to run a production service in the public cloud (we use AWS).
As I’m sure you experience on an hourly basis, the number of technology options for any and every endeavor are almost innumerable and expanding rapidly. As a result, we first came up with a handful of principles for technology selection to put some rigor around our decision making process. These principles have thus far been a helpful guide as we’ve evaluated technology both for our projects as well as our internal development pipeline tools.
- Use the right tool for the right job
- Only invest in areas that add differentiating value to the business
- A technology should have a large community/mindshare and component ecosystem
- There should be a good sized talent pool for a technology
- A chosen technology should be relatively lightweight and focused - there should be as few moving parts as possible
- Each chosen technology should be small and focused enough to be substitutable - at the rate of change in this industry, getting stuck with an outdated piece of technology in one functional area because it happens to implement 5 other functional areas is unacceptable
- The experience between every environment - from production all the way down to the developer’s laptop - should be symmetric
One example of these principles in practice is our developer portal and API documentation site. By focusing on selecting the right tool for the right job and investing wisely, we realized that continuing to run our static documentation Web site on a highly customized content management system running inside of our data center was effectively waste. Firstly, it was technically wasteful to run a static Web site off of a CPU-bound content management system where every request to the origin server required dynamic calculation of HTML. On top of that, the content was stored in a relational database, which is an additional CPU-bound resource that provided no tangible benefit to the problem that the system was trying to address. Secondly, all of the content itself was trapped inside this relational database and reachable only using the CMS’s proprietary user interface. This went against our principle of substitutability. The solution? We extracted from the relational database, converted it to markdown and are about to launch the next version of the Web site as a completely static Web site using Jekyll and GitHub pages. This technology choice helped us to achieve 2 additional benefits regarding the documentation Web site. First, having the site hosted on GitHub enables us to more deeply engage our developer community. Find a bug in the documentation? File an issue on the GitHub site - or better yet, send us a pull request! Second, using Git as our backing store for the site gave us something that very few content management systems actually offer (despite the name content management): version management of content! The power and flexibility that Git provides enable management scenarios from roll back to working branches for larger-scale changes. And by using Jekyll for generating the static site, we can easily provision staging and test versions of the site - whether on a local machine, an S3 bucket, or anywhere in between where files can be stored.
One other example of the principles in context of a technology choice that is very active at the moment relates to Docker. We believe that containers are certainly the path forward for many of our projects. However, our current developer environments are OSX and that operating system does not many capabilities that are required to run Docker development workflows natively. For example, I need to be able to, at a minimum, launch my container and mount the source code directory from my host as a volume in the container so that as I edit my source code, the changes are reflected in the container. On OSX, which with applications such as boot2docker, the interaction between the host and the container goes across a hypervisor boundary, adding a non-trivial amount of friction to the process. As a result, while we are keeping a very close eye on what is happening in the Docker (and Rocket) space, we have not yet moved forward with using Docker for our production software. When we can have a symmetric experience across development and deployment environments, we’ll make that move.
Our Pipeline
While the architecture differs, most of our projects follow a similar development pipeline, which looks like the following.
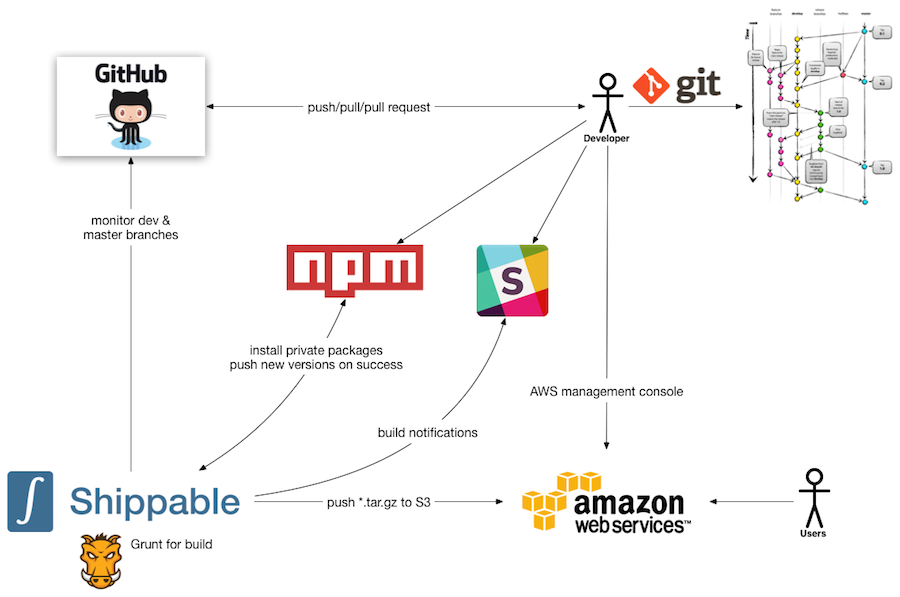
Here’s a high level description of the moving parts.
- We use Git for version control. In terms of how we use Git, we generally follow the process outlined by Vincent Driessen in his most excellent post. We generally maintain 2 persistent branches: master and dev. The semantic for these branches is that any commit that is merged into one of these branches will be deployed to either a pre-production or production environment. As such, all work is done on feature branches which are created off of the dev branch. Getting changes merged from feature branches into dev happens using GitHub’s pull request workflow.
- We use GitHub for Git repository storage. We chose GitHub for a couple of different reasons - these are the ones that are at the top of my mind.
- The GitHub pull request workflow is ideal for our code review process. That said, one enhancement that we would love to see is the ability to draw lines around review iterations (e.g. “I’ve made all of the comments that I plan to make on this pull request - go forth and fix”).
- GitHub has become not just a standard for code hosting, but also a standard authentication provider. In fact, many of the other services that we’re using delegate their own authentication functionality to GitHub.
- Just to underscore that last point, GitHub integrates with pretty much everything. Like I mentioned in the discussion of principles, every specific tool in the chain is replaceable. GitHub continues to add value from the standpoint of the number of additional tools that can seamlessly work with it.
- We use Shippable as our CI environment. The CI server monitors specific branches in our GitHub repositories and triggers builds when there are merges into the monitored branches -or- when there are pull requests created that will result in merges into those monitored branches. Like GitHub, there were a few things that made Shippable attractive to us.
- It integrates seamlessly with GitHub. It handles the token exchange flow with each repository for which you setup a build, making it incredibly simple to get started. It also adds some really nice UI integrations that gets added to pull requests.
- It is built on Docker and containers are a big part of its DNA. As I mentioned earlier, we haven’t yet fully committed to Docker, but we are pretty confident that we will in the future, so knowing that this is a core capability is nice.
- Unlike some CI environments where the CI server and the code are setup independently, Shippable CI builds are based on a Travis-inspired YAML file that travels with the project. Going along with the principle of substitutability and portability, if we decide to later switch CI servers, we don’t have to start from scratch. In fact, ideally, with a few tweaks to our YAML files, we’ll hopefully be able to come back up immediately on a new CI technology.

To give you a better sense of a Shippable CI configuration, here’s the shippable.yml files from one of our projects.
# only trigger ci for dev branch
branches:
only:
- dev
# language setting
language: node_js
# version numbers, testing against two versions of node
node_js:
- 0.10.35
# The path for Xunit to output test reports
env:
global:
- XUNIT_FILE=shippable/testresults/result.xml
- SLACK_ORG=ConcurCTO
- PROJECT=my-project
# Update NPM
before_install:
- npm install -g npm@2.5.1
- ./build/setup_npm.sh $NPME_AUTH_TOKEN
# Create directories for test and coverage reports
before_script:
- mkdir -p shippable/testresults
- mkdir -p shippable/codecoverage
script:
- grunt ci-shippable
- ./build/record_version.sh
# Tell istanbul to generate a coverage report
after_script:
- ./node_modules/.bin/istanbul cover grunt -- -u tdd
- ./node_modules/.bin/istanbul report cobertura --dir shippable/codecoverage/
after_failure:
- python ./build/slack_notifier.py --project $PROJECT --org $SLACK_ORG --token $SLACK_TOKEN
after_success:
- python ./build/slack_notifier.py --project $PROJECT --org $SLACK_ORG --token $SLACK_TOKEN -s
- ./build/publish_npm.sh
Finally, the CI environment is just UNIX - so you can script out whatever you want as a part of your process. There’s no waiting for someone else to implement some hook or feature.
- As you can see from the above YAML file, even with a full-blown CI environment, we still use Grunt for our build automation. This follows the principle of symmetry in that we can also run Grunt locally before committing, thereby giving us a higher degree of confidence before pushing. Our Gruntfile.js is completely agnostic to Shippable with one exception: in order to display test results and code coverage data in its UI, it needs the data formatted by the associated Grunt tasks in a specific manner. Because this format is different than our default, we have the following Shippable-specific test task:
mochaTest: {
'ci-shippable': {
options: {
reporter: 'xunit',
captureFile: 'shippable/testresults/result.xml', // Optionally capture the reporter output to a file
require: 'should'
},
src: ['test/**/*.js', '!test/agentTests-perf.js']
}
}
- Our Grunt-driven build runs the following tasks: JSHint, environment variable setting, and unit test + code coverage.
- When the build completes, regardless of success or failure, a notification is sent to our team’s Slack channel to provide the team with visibility.
- When the build succeeds, a few additional actions also happen
- The NPM version number is incremented using the
npm versioncommand. This command updates the package.json with the new version number and also adds a commit and tag to the Git repository for the project. - The updated package.json file and tag are pushed from the CI server back to the upstream Git repository on GitHub so that the version information is preserved
- The NPM package for the project itself is published to a private (AWS-hosted) installation of NPM Enterprise. So that it can be consumed by additional projects. This has proven incredibly helpful for internal utilities and libraries.
- The NPM version number is incremented using the
- The zipped tarball is finally pushed into a private S3 bucket which is used by our instance startup scripts to deploy updates of the application. This is currently done in a custom manner (we have the version and time stamp as a part of the filename and the startup script checks to see whether it has the latest version and if not, gets it), but in the near future, our plan is to take advantage of AWS’s Code Deploy feature (and ECS deployment even farther down the road). This will give us better support for things like rollback, ELB rotation, etc.
- Finally, our team uses the AWS Management Console for activities such as monitoring the health of the system using CloudWatch.
Like I have probably mentioned a few times, there are still some areas where we are investing in to continue improving our process and tooling.
- Docker all the things! As soon as we can take advantage of Docker in a manner that aligns with our principles, we’re there.
- CloudFormation for more quickly stamping out new environments (not just individual compute instances)
- Running tools such as many of those in the Netflix toolbelt (SimianArmy, Security Monkey, etc.)
The thing I like about what we have at present when I think about some of these future aspirations is that the principles above actually give us the ability to move forward quickly on any of these without really having to wait for some big, vendor-specific piece of software to add capabilities. When we find something that will move our workflow forward, we’ll add it. If we later decide it’s not helping, we’ll remove it. If we find something better, we’ll replace it.